The current state of storage proofs

12/05/23
Authors: Parti, Skeletor Spaceman

The EVM as the verifier
An inclusion proof is a computational operation that ensures, with a high confidence level, that a certain claim value belongs to a certain dataset represented by a commitment. A storage proof is an inclusion proof for a storage slot in an EVM contract. For a more detailed explanation on how these works, we recommend checking the following link:
Ethereum is a transparent and decentralized VM. As such, it is the ideal platform to act as a trustless verifier. If Ethereum is convinced, so should we. But what does it mean for Ethereum to be a verifier? Verification in a protocol is a series of deterministic steps conducted on a series of inputs. In particular, we can write a verification program in the bytecode of a Smart Contract.
Storage proofs are a powerful tool to minimize trust, and Ethereum provides an efficient design to prove them (Merkle Patricia Tries). Nonetheless, there hasn’t been much actual use. And that’s mainly because of the following reasons:
- State root availability:
- In space: There is no way to query block header information cross-chain.
- In time: EVMs only allow users to query block header information up to 256 blocks back
- Verification costs: Current verifier implementations consume approximately 200k in gas.
This report will analyze the current status of storage-proof solutions for increasing availability and costs.

State root availability
In space: Cross-chain state root
To execute the storage proof verification, it is necessary to have a reliable way to read the state root from the source chain in the destination chain. Light Client Proofs do not prove execution or storage but consensus (validator signatures) and use the beacon root (instead of the state root). These proofs assert that a specific state root R corresponds to a finalized block. In other words, a proof must prove that a particular state is valid and corresponds to the correct (finalized) fork choice. Unfortunately, the beacon root is currently not included in the execution layer, but it's expected to be. So, how do we get this information to another chain?
One basic method to prove the consensus of chain A in the execution layer of chain B is to run an on-chain Light Client of chain A inside chain B. This is, of course, extremely expensive to run. To gain some intuition on why, consider that Ethereum consensus uses BLS signatures on a BLS12-381 curve, which are not included as a precompile in EVMs. Even if the Light Client verified the signatures of the sync committee only, it is still prohibitory costly. Here is where zk comes into play.

Succint developed a contract that verifies a zk-proof of consensus, where anyone can post a zkSNARK attesting that the sync committee has signed a block header. Their design also requires keeping track of the current sync committee, which is also done via a zkSNARK. The protocol is deployed on Ethereum and other chains, but the light client updates is operating frequently only in Goerli. Each update in Ethereum costs 300k in gas. They enable light client proofs of Ethereum and Gnosis to Ethereum, Gnosis, Arbitrum, Avalanche, Binance, Optimism and Polygon (look here for the addresses).
Bravis is using a similar sync committee model, but couldn’t find the light client contracts to figure out their gas cost.
Conversely, Lagrange questions the security of a sync-committee-based light client (such as the one used by Succint), as they are exposed to corruption risk. Moreover, they claim that it’s impossible to maintain a zkSNARK system that proves Casper Finality (Succint claims their SNARK include finality, so one of the two must be lying). To safely and efficiently update the finalized block header information, they use a node’s network restaked using Eigenlayer or other providers. This method also allows integrating other chains that don’t necessarily have Ethereum consensus. They are still on production.
Herodotus is another key protocol here. They use native L1←→L2 message passing to synchronize block hashes between chains. The process is quite complex, involving multiple transactions over two contracts (full explanation can be found here). The total gas consumed is almost 4M (here and here).
It’s worth noticing that L2s can post the BLOCKHASH from L1 directly on L2 by using a deposit function, as an arbitrary message. This needs to be actively supported, and none is doing it at the time of writing, as the cost would be pretty high (approximately $300k per rollup per year). Nonetheless, there is no need to update every single root: time batching could do wonders on saving unnecessary costs. Shared sequencer could also address this problem.
An alternative design would be to modify the client from the L2 and introduce an opcode/precompile that can access the BLOCKHASH directly without a deposit (leverage the fact that the sequencer is already reading the L1 state).
In time: Historical state roots
The EVM allows contracts to fetch BLOCKHASH data up to 256 blocks back (less than 1 hour). This is not enough to make storage proofs of things like “who owned a certain ERC20 2 months ago?”, which could be used for a trustless airdrop distribution.
Axiom, Relic and Herodotus are working on storing these historical roots on-chain using zkSNARKs. They both have a similar flow, where users update the latest roots with proof that a contract verifies. If the roots are valid, they get inserted into a Merkle Mountain Range. Herodotus also stores the root cache into an MMR but cross-chain using STARKs.
⛰️ Merkle Mountain Range: Once verified, the roots must be stored on-chain to run the other verifications (storage proofs, for instance). Nonetheless, keeping such a registry is expensive. There are several ways to optimize this point, with the most popular approach being Merkle Mountain Range structures, an efficiently updatable Merkle tree of roots (see this explanation, Axiom implementation, the Herodotus implementation in Cairo and polytope Solidity implementation).
Verification costs
As we mentioned, our goal is to prove the value of a certain storage value from a certain contract in a different chain. There are at least two ways to verify this on-chain:
- generate storage proof → verify it on-chain
- generate storage proof → generate zk proof for it → verify it on-chain
During the last few years, we have seen enormous technical advances in optimizing verification processes. The field of zk proofs has gained a lot of traction, in a big part due to their brief verification step. These proofs outsource the heavy computation to the prover to make verification as simple as possible.

This succinctness is particularly appealing when dealing with the EVM, as computation requires gas. In what follows, we will describe some possible approaches to dealing with storage proofs in this context.
In this blog post, Vitalik compares five ways to tackle verification:
- Merkle proofs
- General-purpose zkSNARKs
- Special-purpose proofs (e.g. KZG)
- Verkle proofs
- Direct reading
Both zkSNARKs and KZG allow for proof aggregation, further reducing user costs.
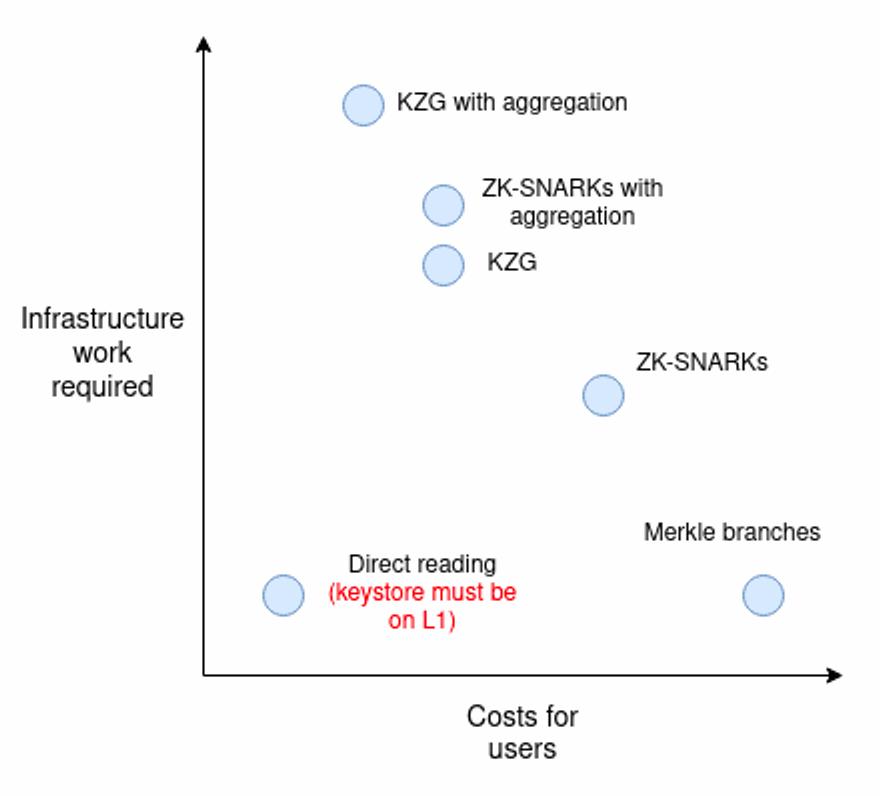
In what follows, we will focus on the existing approaches to tackle this verification step. Even though storage proofs (with or without zk) are the most secure method, we will also consider other options in our analysis. For each, we will analyze the tradeoffs, possibilities, costs and state of development.
Direct Merkle Proofs
MPT verification refers to contracts that can compute the whole storage proof from the Ethereum Merkle Patricia Trie on-chain. There are several working implementations of MPT verifiers written in Solidity. We recommend checking the Lido and polytope implementations. See here for more details.
It’s easy to generate proofs for any storage slot using the RPC providers’ eth_getProof() method. Storage-proof verification implementations require approximately 200k gas, which is considerable for Ethereum but not so much for L2s.
From the existing protocols we mentioned, Relic and Herodotus use direct MPT proofs against the verified roots. You can check out Relic’s optimized Solidity library and Herodotus Fact Registry in Starknet. I also found this repo in Noir for Ethereum MPT verification: https://github.com/aragonzkresearch/noir-trie-proofs/

General purpose zkProofs: zkSNARKs
SNARKs are argument systems that allow anyone to verify a program satisfaction claim in a non-interactive and succint way. This means that a prover can convince a verifier that they have an input that makes a computer program output a target value with a concise and easy-to-evaluate proof.
Storage proofs are only a particular use case for SNARKs, where a proof is crafted for the MPT storage proof computation. The idea here is to embed the MPT verification into a more succint SNARK.
There are many types of SNARK implementations, each with its corresponding costs. Some popular implementations in the EVM context are Plonky2 (which combines PLONK with FRI into a super efficient recursive SNARK) and UltraPLONK (more battle-tested, used by zkSync and Aztec, among others).
I strongly recommend this resource for anyone interested in a technical dive into the subject.
Coprocessors
Coprocessors are instances that work like an off-chain VM extension that can execute heavy computation based on on-chain data. These coprocessors allow the outsource storage proofs (and other kinds of computation) from the chain and then submit a zk proof that is cheaper to verify. Notice the definition of a coprocessor is quite vague, which has lead to some discussions. Storage proofs are just a particular use case for coprocessors but also the most common use case.
Axiom is the most popular player in this design space, specially tailored for historical proofs inside Ethereum. They have a library for creating custom circuits for storage proofs. They use Halo2 arithmetization (a method to convert programs to arithmetic circuits) and KZG polynomial commitments. Users must offer a reward to initiate a query, similar to our module design. They recently announced their v2, which also includes transaction and receipts proofs.
At the time of writing, they have deployed their contracts on mainnet only. A potential integration would require deploying the contracts on the different networks, which is not that easy to do, as verification requires query access to the state roots cache (MMR implementation).
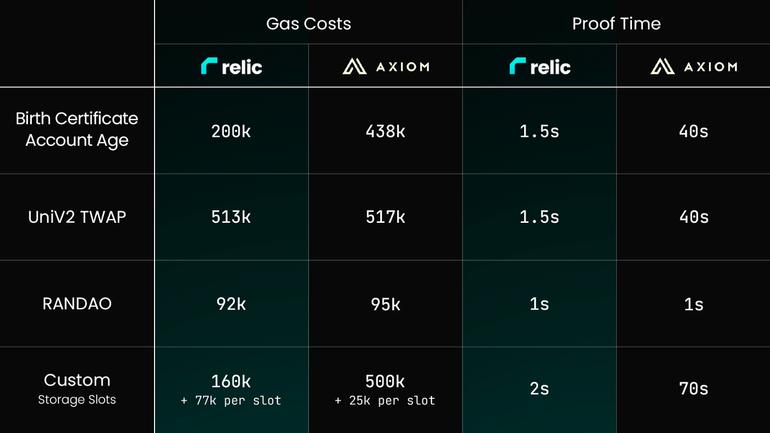
Also, note that the current implementation consumes above 500k gas per query answer, even more than the current MPT implementations. Axiom has, of course, a lot of additional benefits, such as allowing queries to go back in time.
Gas comparison for different proofs. Image taken from Relic’s documentation:
Brevis also does zk storage proofs, but using Groth16 based circuits. It can also be used to prove claims using the Receipts and Transaction Tries. They have a working demo which allows to generate storage proofs for Ethereum and then submit the proof to BSC chain (check verifier contract here).
Herodotus has its own implementation for storage proofs. It’s already deployed and running, but it’s extremely expensive to verify (over 5M gas at the time of writing).
RISC Zero allows users to verify general computation written in Rust using STARKs and their Bonsai proving system. They also built Zeth, their own block and state prover, aka a type 0 zk-rollup. In theory, the gas costs are scalable (around 200k in callback and 30k in request).
On a similar line, fhEVM aims to create a coprocessor for private smart contract functionalities. RISC Zero and fhEVM are still in an early stage and not production-ready.
Batching proofs: zk MapReduce & Recproofs
The goal is to have a proof construction method optimized for generating large-scale batch storage proofs.
zkMapReduce allows anyone to prove they’ve performed specific computations on a dataset without revealing the dataset itself or the intermediate steps. The proof has to prove the existence of the underlying data (a storage proof) and the result of a computation on it. Proofs use vector commitment schemes, making them suitable for proving distributed computation, such as SQL or MapReduce.
This method allows the merging of storage proofs from different chains into a single proof, simultaneously acting as a coprocessor for multiple chains. This is what Lagrange uses to act as an n-1 bridge. The bad news is that updating existing proofs is expensive, which Lagrange’s Recproofs aim to solve.
Recproofs are a particular Merkle-tree-based vector commitment scheme that allows proof batching for a group of leaves using recursive SNARKs. This is particularly useful for large datasets and allows efficient proof updates for MapReduce systems. To achieve this, they use folding schemes, where a set of proofs gets compacted into a single proof of proofs. What’s important to know is that this proof is O(log n) with n the number of underlying proofs. We could expect Lagrange to implement Recproofs to improve their system’s proof update process.
Lagrange is yet to be operating, so we still have yet to determine what the gas cost for this system will be for the users. Due to batching, we expect systems like this to become more relevant with the number of storage proofs.
Other approaches
HyperOracle defines itself as programable zkOracle. It will allow users to query any information on-chain, including state or storage proofs from Ethereum, using zk-verified methods. These proofs can also work for historical data (beyond the 256 blocks). The product is still in construction, and we could not find details on the zk tools being used, nor expected gas cost or latency.
Specific purpose zkProofs: KZG
KZG allow the construction of efficiently updatable storage proofs. Dankrad does a great job of summarizing KZG in this post. The basic intuition works as follows:
- Given a dataset , it’s possible to create a polynomial such that interpolates to the dataset at the powers of the root of unity in mod . The interpolation expects that , and can be done using Lagrange.
- A commitment to is an elliptic curve point defined as with the generator point of the curve, the i-th degree coefficient of the polynomial and the i-th point of the trusted setup.
- To create a proof for the claim , the prover must generate a polynomial , and then commit to it . This polynomial is well defined if and only if .
- Verifier checks the equation in the elliptic curve using pairings :
Efficient updates
As we mentioned, an attractive property of KZG is that proofs can be efficiently updated: if a specific value wants to , then the old commitment to can be updated to a commitment to as follows: with the Lagrange polynomial that equals 1 at and 0 on . Notice can be precomputed by the prover ( commitments). The verifier, on the other hand, will not store the commitments but can receive a KZG commitment or a Merkle proof for the set to prove correctness. Hence, this protocol enables efficient updates, which would be ideal for our concrete application.
Additionally, two KZG proofs can be merged into a single one, which would simplify our current two step verification contracts into a single one.
Implementations of KZG in Solidity are still in the experimental stage. Most implementations focus on its application for EIP-4844 rather than for storage proofs. Also, KZG is worth it if batching can be done, which will probably not happen for the PoC.

Verkle Proofs
Verkle trees are improvements over Merkle Patricia Tries for storing key-value mappings. It uses stacked Polynomial or Inner Product commitments. These structures are likely to be incorporated into Ethereum as the new state tree.
A SNARK can be generated for Verkle tree inclusion proofs, resulting in lower prover cost than current Merkle structures. However, implementations are still far away to consider.
Direct Reading
It is possible to enable static calls from L2 contracts to L1 contracts. This would require a special opcode or precompile in the L2. Remember that sequencers are already aware of the L1 state, as they have to track the rollup contract, so it’s mostly an implementation challenge.
Optimism has recently opened a request for a proof of concept on this line.
Further Optimizations
Consensus
Some protocols can answer state queries using consensus instead of cryptographic verification. This method introduces a considerable amount of trust but also reduces the cost of operations and latency.
Succint is following this design choice by leveraging its attestation network. The product was still not ready at the time of writing, so we could not find precise information on the gas costs. We did, however, find this sentence in their documentation:
Many developers rely on oracles to power liquidations or other very latency sensitive parts of their protocol. These developers want the lowest-possible latency for their oracle requests. While there have been tremendous leaps in zk proof technology, the proof generation time is still ultimately too slow for many use-cases. Also, verifying a zk proof is cheap, however for minimized gas costs, verifying signatures from a network is even cheaper (generally 240k gas vs. 30k gas if our network has 15 validators). Thus many developers prefer a committee based approach for minimal latency and minimal gas costs.
We will advise against this for now, even though it could reduce enormously cost and latency because we consider it is not worth the additional security risks.
Optimistic layer
A middle ground between consensus methods and full verification is to use an optimistic system where users can request and receive a state update. This system should include a verification method with a full procedure (direct MPT or zk) in case of a dispute. Such a mechanism aims to lower the gas cost of storage proofs with only a minor increase in trust (1-N will dispute).
An optimistic layer has an additional price to pay, which is latency. The mechanism requires a long time window to ensure agents have time to dispute. The longer the time window, the safer the optimistic system, but the higher the request latency.
Shared sequencers
Shared sequencing is one of the hottest topics in web3 at the moment. As sequencers usually play a huge role in communication between chains, it is unsurprising that a shared sequencer can optimize communication by implementing shared proofs.
This design would have a similar end goal to what Lagrange does with N-1 communication but using simpler aggregated proofs. These thoughts are still early and being actively discussed.
This approach is currently out of scope from this project but could be considered if shared sequencer become a thing.
Takeaways
We will now summarize and add some comments on the status of storage proofs.
- State root availability: There is no doubt Ethereum’s state root will be the most popular among the EVMs, and hence the most widely available. Moreover, picking Ethereum as the source chain and rollups as destination chains also means verification costs will be paid on cheaper networks. This should have a significant impact on the design of systems requiring storage proofs, with Spoke-Hub architectures becoming more widespread.
The only solution currently posting the root and with a relatively low verification cost is Succint (300k gas average per update). Succint only bridges the state root to Optimism, Arbitrum, Polygon, Gnosis, BSC and Avalanche. At the moment, their operators charge no fee for the update, but an on-demand integration would probably require some kind of incentive.
An alternative way of addressing this issue is using a bridge, which usually costs around 200k for these message passing. Connext has the upper hand regarding message security among the top candidates, as they implement Merkle verification methods on top of AMBs, instead of signature aggregations like the vast majority.
- Improve proof efficiency: One main point we analyzed was the proof cost. We noticed that MPT verifiers are cheaper than existing ZK single-proof implementations. There are two main approaches to reducing verification costs for the latter:
- Updatable proofs: as we mentioned, MPT proofs need to be recomputed and rechecked from scratch every time something changes, and it doesn’t matter if it’s just one or one million changes. KZG and Recproofs are two protocols that address this issue. In particular, KZG is more straightforward to implement and probably more efficient for the number of proofs we expect, while Recproofs shines for larger datasets.
- Proof batching: some verification methods allow batching of several proofs into one. This is possible with KZG and SNARK using different methods (e.g. folding scheme). Currently, there are no efficient implementations for either approach in the context of storage proofs. It's out of our scope of this work to develop one. These proofs usually have a large cost for single executions and then scale slowly. This means that, for single proofs, MPT verification will stay the most competitive, but there is a number of proofs at which ZK methods become more efficient.
- Optimistic layer: One easy way to reduce verification costs with only a small trust increase is using optimistic oracles. The idea here is to trust a bonded proposer with the correct updated information and then let anyone (bonded agent) dispute the answer. In a dispute, conflict resolution involves running the complete verification. In that case, the gas cost of verification would be deducted from the losing side’s bond.
The optimistic layer would allow the exchange of two MPT verifications, which are close to 200K gas each, for a request and update, which will be cheaper. Moreover, optimistic systems can update several users simultaneously (batching), with practically the same gas cost.
A negative factor introduced by optimistic layers is latency, as a safe system requires time for disputers to act. Latency could be a problem for the module in the case of heavy activity, which may not be the case at the beginning. What’s more, lowering the gas cost of the process can bootstrap users in the same way liquidity incentives do. We could expect a first optimization to use optimistic layers and eventually move to more advanced KZG/SNARK systems (lower latency) with aggregation when the number of users justifies the total cost.
There are currently no optimistic oracles that enable custom resolution methods. We, at Wonderland, are actively developing Prophet together with Optimism, which will be a framework that enables this use case. Information on the gas cost will be available soon.
It’s also possible to create a custom dispute system for this particular project, which could be more gas-efficient. The issue with that would be to bootstrap activity from bonded actors. That’s why Prophet could be a better fit, even if it means using a bit more gas.
For the PoC, we expect to work on sidechains only, meaning the total gas cost of MPT verification will not be prohibitive. Similarly to the zk-methods, an optimistic layer would make much more sense for verifying in Ethereum (Home Chains different than mainnet). Implementing said layer would be a manageable experiment for a future Home chain generalization at this point.
- Potential ecosystem optimization: beyond improving verification methods, the ecosystem is currently discussing several architecture changes that might simplify the • problem’s scope.
- Rollups might make the Ethereum state root available: many protocols will be interested in having state root availability for different applications, so it should not be surprising to see rollups or AMBs making this value globally available. This would allow us to reduce the costs further (or increase the frequency), as payments could be batched with different services.
- Rollups might enable direct reading eventually, which would simplify the whole verification. Direct reading would be an enormous factor in favour of keeping Ethereum as the Home Chain, but would still require dedicated solutions for non-L2 chains.
- Shared sequencing or data availability layers can act as a way of sharing Home chain verification among several chains, reducing the cost for each even further.
- If implemented, Verkle tree structures will completely change (for the better) the whole verification algorithm. The module, together with many other products using storage proofs, would require a major update.